熱門文章
- Bootstrap安裝教程 (發布時間:2021-06-25 17:03:51)
- bootstrap框架怎么用?10分鐘教你學會使用bootstrap開發網頁 (發布時間:2021-06-25 16:32:17)
- Bootstrap5 出來了,我應該學習Bootstrap4還是Bootstrap5? (發布時間:2021-05-02 13:21:53)
最新文章
- 我通過重新學習 HTML 學到的東西 (發布時間:2021-06-30 17:37:25)
- 設計師:注意你的語言 (發布時間:2021-06-30 17:28:00)
- 設計全方位搜索 (發布時間:2021-06-30 17:12:41)
- CSS 垂直媒體查詢的用例 (發布時間:2021-06-30 17:05:47)
- 世界上最受歡迎的排版博客現在有一家商店 (發布時間:2021-06-30 17:05:31)
- 每天學習前端 Web 開發的旅程 (發布時間:2021-06-30 16:31:02)
- Bootstrap安裝教程 (發布時間:2021-06-25 17:03:51)
- bootstrap框架怎么用?10分鐘教你學會使用bootstrap開發網頁 (發布時間:2021-06-25 16:32:17)
- 2021年世界上制造業網站設計的 5 個最佳范例 (發布時間:2021-06-22 15:29:54)
- CMS 的興起和“網站管理員”的衰落 (發布時間:2021-06-22 15:26:45)
Google搜索引擎蜘蛛抓取份額是什么?抓取份額是由什么決定的?
發布時間:2021-06-22 15:26:45
一月份時,Google新的SEO代言人Gary Illyes在Google官方博客上發了一篇帖子:What Crawl Budget Means for Googlebot,討論了搜索引擎蜘蛛抓取份額相關問題。對大中型網站來說,這是個頗為重要的SEO問題,有時候會成為網站自然流量的瓶頸。
今天的帖子總結一下Gary Illyes帖子里的以及后續跟進的很多博客、論壇帖子的主要內容,以及我自己的一些案例和理解。
強調一下,以下這些概念對百度同樣適用。
什么是搜索引擎蜘蛛抓取份額?
顧名思義,抓取份額是搜索引擎蜘蛛花在一個網站上的抓取頁面的總的時間上限。對于特定網站,搜索引擎蜘蛛花在這個網站上的總時間是相對固定的,不會無限制地抓取網站所有頁面。
抓取份額的英文Google用的是crawl budget,直譯是爬行預算,我覺得不太能說明是什么意思,所以用抓取份額表達這個概念。
抓取份額是由什么決定的呢?這牽扯到抓取需求和抓取速度限制。
抓取需求
抓取需求,crawl demand,指的是搜索引擎“想”抓取特定網站多少頁面。
決定抓取需求的主要有兩個因素。一是頁面權重,網站上有多少頁面達到了基本頁面權重,搜索引擎就想抓取多少頁面。二是索引庫里頁面是否太久沒更新了。說到底還是頁面權重,權重高的頁面就不會太久不更新。
頁面權重和網站權重又是息息相關的,提高網站權重,就能使搜索引擎愿意多抓取頁面。
抓取速度限制
搜索引擎蜘蛛不會為了抓取更多頁面,把人家網站服務器拖垮,所以對某個網站都會設定一個抓取速度的上限,crawl rate limit,也就是服務器能承受的上限,在這個速度限制內,蜘蛛抓取不會拖慢服務器、影響用戶訪問。
服務器反應速度夠快,這個速度限制就上調一點,抓取加快,服務器反應速度下降,速度限制跟著下降,抓取減慢,甚至停止抓取。
所以,抓取速度限制是搜索引擎“能”抓取的頁面數。
抓取份額是由什么決定的?
抓取份額是考慮抓取需求和抓取速度限制兩者之后的結果,也就是搜索引擎“想”抓,同時又“能”抓的頁面數。
網站權重高,頁面內容質量高,頁面夠多,服務器速度夠快,抓取份額就大。
小網站沒必要擔心抓取份額
小網站頁面數少,即使網站權重再低,服務器再慢,每天搜索引擎蜘蛛抓取的再少,通常至少也能抓個幾百頁,十幾天怎么也全站抓取一遍了,所以幾千個頁面的網站根本不用擔心抓取份額的事。數萬個頁面的網站一般也不是什么大事。每天幾百個訪問要是能拖慢服務器,SEO就不是主要需要考慮的事了。
大中型網站可能需要考慮抓取份額
幾十萬頁以上的大中型網站,可能要考慮抓取份額夠不夠的問題。
抓取份額不夠,比如網站有 1 千萬頁面,搜索引擎每天只能抓幾萬個頁面,那么把網站抓一遍可能需要幾個月,甚至一年,也可能意味著一些重要頁面沒辦法被抓取,所以也就沒排名,或者重要頁面不能及時被更新。
要想網站頁面被及時、充分抓取,首先要保證服務器夠快,頁面夠小。如果網站有海量高質量數據,抓取份額將受限于抓取速度,提高頁面速度直接提高抓取速度限制,因而提高抓取份額。
百度站長平臺和Google Search Console都有抓取數據。如下圖某網站百度抓取頻次:
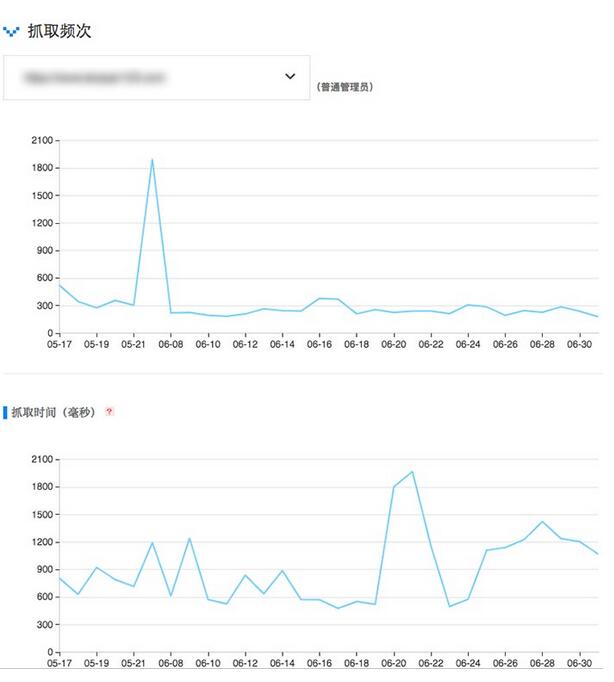
上圖是SEO每天一貼這種級別的小網站,頁面抓取頻次和抓取時間(取決于服務器速度和頁面大小)沒有什么大關系,說明沒有用完抓取份額,不用擔心。
有的時候,抓取頻次和抓取時間是有某種對應關系的,如下圖另一個大些的網站:
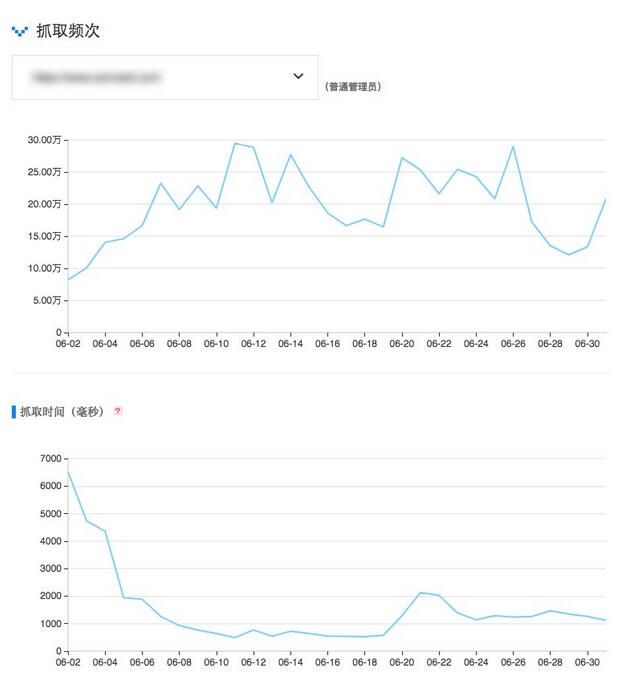
可以看到,抓取時間改善(減小頁面尺寸、提高服務器速度、優化數據庫),明顯導致抓取頻次上升,使更多頁面被抓取收錄,遍歷一遍網站更快速。
Google Search Console里更大點站的例子:
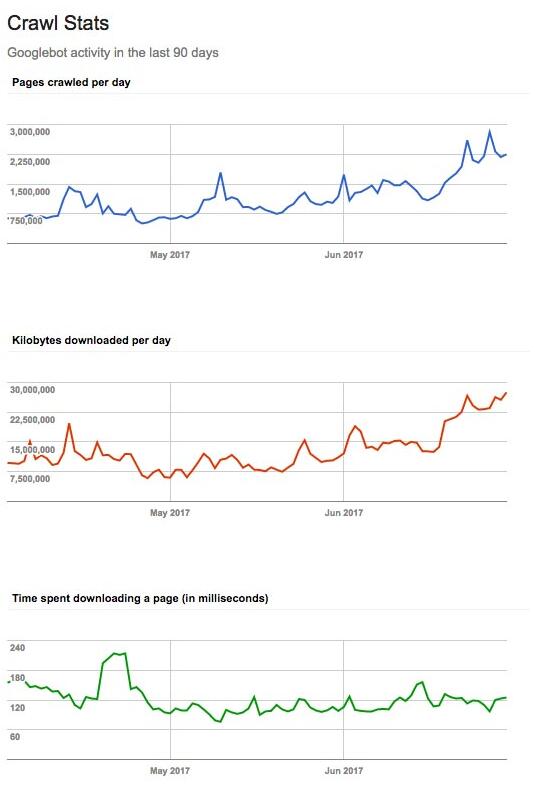
最上面的是抓取頁面數,中間的是抓取數據量,除非服務器出錯,這兩個應該是對應的。最下面的是頁面抓取時間。可以看到,頁面下載速度夠快,每天抓取上百萬頁是沒有問題的。
當然,像前面說的,能抓上百萬頁是一方面,搜索引擎想不想抓是另一方面。
大型網站另一個經常需要考慮抓取份額的原因是,不要把有限的抓取份額浪費在無意義的頁面抓取上,導致應該被抓取的重要頁面卻沒有機會被抓取。
浪費抓取份額的典型頁面有:
大量過濾篩選頁面。這一點,幾年前關于無效URL爬行索引的帖子里有詳細討論。站內復制內容低質、垃圾內容日歷之類的無限個頁面
上面這些頁面被大量抓取,可能用完抓取份額,該抓的頁面卻沒抓。
怎樣節省抓取份額?
當然首先是降低頁面文件大小,提高服務器速度,優化數據庫,降低抓取時間。
然后,盡量避免上面列出的浪費抓取份額的東西。有的是內容質量問題,有的是網站結構問題,如果是結構問題,最簡單的辦法是robots文件禁止抓取,但多少會浪費些頁面權重,因為權重只進不出。
某些情況下使用鏈接nofollow屬性可以節省抓取份額。小網站,由于抓取份額用不完,加nofollow是沒有意義的。大網站,nofollow是可以在一定程度上控制權重流動和分配的,精心設計的nofollow會使無意義頁面權重降低,提升重要頁面權重。搜索引擎抓取時會使用一個URL抓取列表,里面待抓URL是按頁面權重排序的,重要頁面權重提升,會先被抓取,無意義頁面權重可能低到搜索引擎不想抓取。
最后幾個說明:
鏈接加nofollow不會浪費抓取份額。但在Google是會浪費權重的。noindex標簽不能節省抓取份額。搜索引擎要知道頁面上有noindex標簽,就得先抓取這個頁面,所以并不節省抓取份額。canonical標簽有時候能節省一點抓取份額。和noindex標簽一樣,搜索引擎要知道頁面上有canonical標簽,就得先抓取這個頁面,所以并不直接節省抓取份額。但有canonical標簽的頁面被抓取頻率經常會降低,所以會節省一點抓取份額。抓取速度和抓取份額不是排名因素。但沒被抓取的頁面也談不上排名。