熱門文章
- Bootstrap安裝教程 (發(fā)布時間:2021-06-25 17:03:51)
- bootstrap框架怎么用?10分鐘教你學會使用bootstrap開發(fā)網(wǎng)頁 (發(fā)布時間:2021-06-25 16:32:17)
- Bootstrap5 出來了,我應該學習Bootstrap4還是Bootstrap5? (發(fā)布時間:2021-05-02 13:21:53)
最新文章
- 我通過重新學習 HTML 學到的東西 (發(fā)布時間:2021-06-30 17:37:25)
- 設(shè)計師:注意你的語言 (發(fā)布時間:2021-06-30 17:28:00)
- 設(shè)計全方位搜索 (發(fā)布時間:2021-06-30 17:12:41)
- CSS 垂直媒體查詢的用例 (發(fā)布時間:2021-06-30 17:05:47)
- 世界上最受歡迎的排版博客現(xiàn)在有一家商店 (發(fā)布時間:2021-06-30 17:05:31)
- 每天學習前端 Web 開發(fā)的旅程 (發(fā)布時間:2021-06-30 16:31:02)
- Bootstrap安裝教程 (發(fā)布時間:2021-06-25 17:03:51)
- bootstrap框架怎么用?10分鐘教你學會使用bootstrap開發(fā)網(wǎng)頁 (發(fā)布時間:2021-06-25 16:32:17)
- 2021年世界上制造業(yè)網(wǎng)站設(shè)計的 5 個最佳范例 (發(fā)布時間:2021-06-22 15:29:54)
- CMS 的興起和“網(wǎng)站管理員”的衰落 (發(fā)布時間:2021-06-22 15:26:45)
高并發(fā)網(wǎng)站架構(gòu)設(shè)計
發(fā)布時間:2021-06-22 15:26:45
所謂高并發(fā),指的是同一時間可以處理大量的WEB請求,這個指標用來衡量一個架構(gòu)的體量和性能。這里的大量如何評估呢?1000算不算?10000算不算?
對于中小型的站點來說,可能并發(fā)100多就很不錯了,但對于像淘寶這樣的大型站點,單憑一個接口調(diào)用的量就有可能達到百萬的并發(fā)。在雙11這樣的大型活動場景里,淘寶的并發(fā)請求數(shù)都能達到上億次,這樣的體量無論是在國內(nèi)還是在國際都是排在前列的。而本章節(jié)要講述的內(nèi)容是如何設(shè)計一個可以承載巨量并發(fā)請求的架構(gòu)。
要想設(shè)計一個高并發(fā)的架構(gòu),首先要搞清楚架構(gòu)的分層,因為每一個層面都有可能造成影響高并發(fā)的瓶頸點。找到瓶頸點后,只要把瓶頸點解除,自然會提升整個架構(gòu)的并發(fā)處理能力。我們先來看一個綜合分層的架構(gòu)圖:
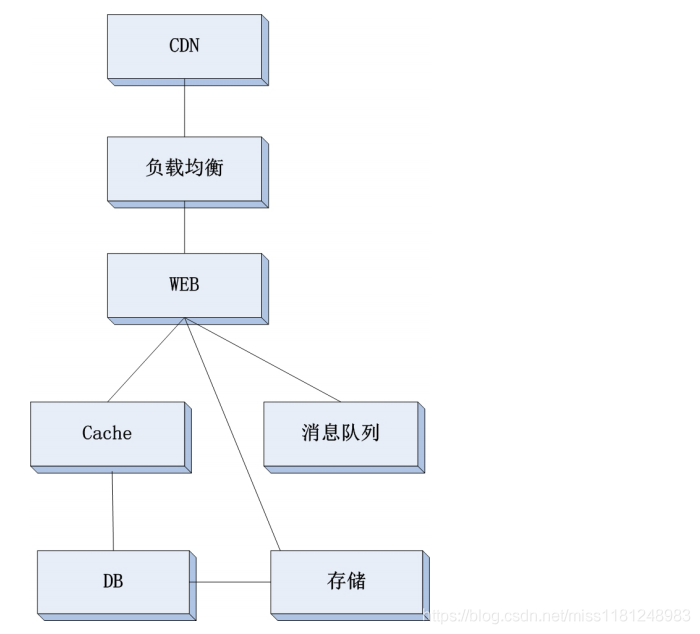
1. CDN
對于大型網(wǎng)站來說增加CDN這一層是非常有必要的,CDN(Content Delivery Network,內(nèi)容分發(fā)網(wǎng)絡(luò)),它屬于網(wǎng)絡(luò)范疇的一個技術(shù),它依靠部署在各個區(qū)域的邊緣服務(wù)器,實現(xiàn)負載均衡、內(nèi)容分發(fā)調(diào)度等功能。它使得用戶就近獲取內(nèi)容,降低網(wǎng)絡(luò)堵塞,提供用戶訪問響應速度。
來舉一個通俗點的例子:小明公司做了了一個針對全國用戶的業(yè)務(wù),服務(wù)器放在了北京,但是深圳用戶在訪問網(wǎng)站的時候非常卡頓,有時候甚至訪問不到。經(jīng)排查,造成該問題的原因是深圳用戶所在網(wǎng)絡(luò)到北京的機房延遲非常大。小明想到了一個辦法,他在深圳的某機房假設(shè)了一臺服務(wù)器,把北京服務(wù)器上的文件傳輸?shù)缴钲诘姆?wù)器上,當深圳用戶訪問網(wǎng)站時,讓該用戶直接去訪問深圳的服務(wù)器,而不是訪問北京的服務(wù)器。同理,其他城市也效仿深圳假設(shè)了類似的服務(wù)器,這樣全國各地的用戶訪問公司業(yè)務(wù)都很順暢了。
例子中的解決方案其實就是CDN實現(xiàn)原理,當然,真正的CDN技術(shù)要復雜得多,要考慮很多問題,比如邊緣服務(wù)器的分布、機房的網(wǎng)絡(luò)、帶寬、服務(wù)器的存儲、智能DNS解析、邊緣服務(wù)器到真實服務(wù)器之間的網(wǎng)絡(luò)優(yōu)化、靜態(tài)和動態(tài)資源的區(qū)分、緩存的優(yōu)化、壓縮、SSL等等問題。關(guān)于這些細節(jié)技術(shù)我不做過多解釋,但希望大家能通過我的描述了解CDN在架構(gòu)中存在的意義。
CDN是處于整個架構(gòu)體系中最前端的一層,它是直接面對用戶的,CDN會把靜態(tài)的請求(圖片、js、css等)直接消化掉,然后把動態(tài)的請求往后傳遞。實際上,一個網(wǎng)站(比如,淘寶網(wǎng))超過80%的請求都是靜態(tài)的請求,那也就意味如果前端架設(shè)了CDN,即使并發(fā)1億,也只有2000萬到了后端的WEB上。那么你可能會問,CDN能支持8000萬的并發(fā)嗎?這個主要取決于CDN廠商的實力,如果他們搞10000個節(jié)點(即邊緣服務(wù)器),每個節(jié)點上消化8000并發(fā),如果搞10萬個節(jié)點,每個節(jié)點只需要消
化800個并發(fā)而已。然而,一臺普通的Nginx服務(wù)器(配置2核CPU4G內(nèi)存)輕松處理5萬個并發(fā)(前提是做過優(yōu)化,并且處理的請求是靜態(tài)請求、或者只是轉(zhuǎn)發(fā)請求)。
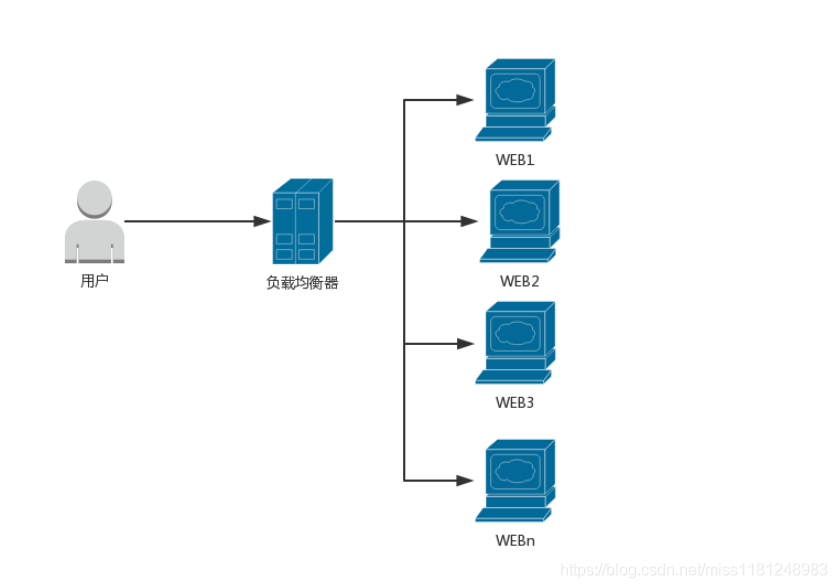
2. 負載均衡
這一層,其實就是一個反向代理(或者叫做分發(fā)器),它的主要作用是把用戶的請求按照預設(shè)的算法發(fā)送給它后面的WEB服務(wù)器。該層在實現(xiàn)上大致分為兩類:四層和七層(網(wǎng)絡(luò)OSI七層模型),Nginx的負載均衡就屬于七層,而LVS屬于四層。從吞吐量上來分析,四層的負載均衡更有優(yōu)勢。
所以,要想實現(xiàn)高并發(fā),負載均衡這一層必須要使用四層技術(shù),其中LVS就是一款不錯的開源負載均衡軟件。LVS有三種實現(xiàn)模式:
1)基于iptables的NAT模式
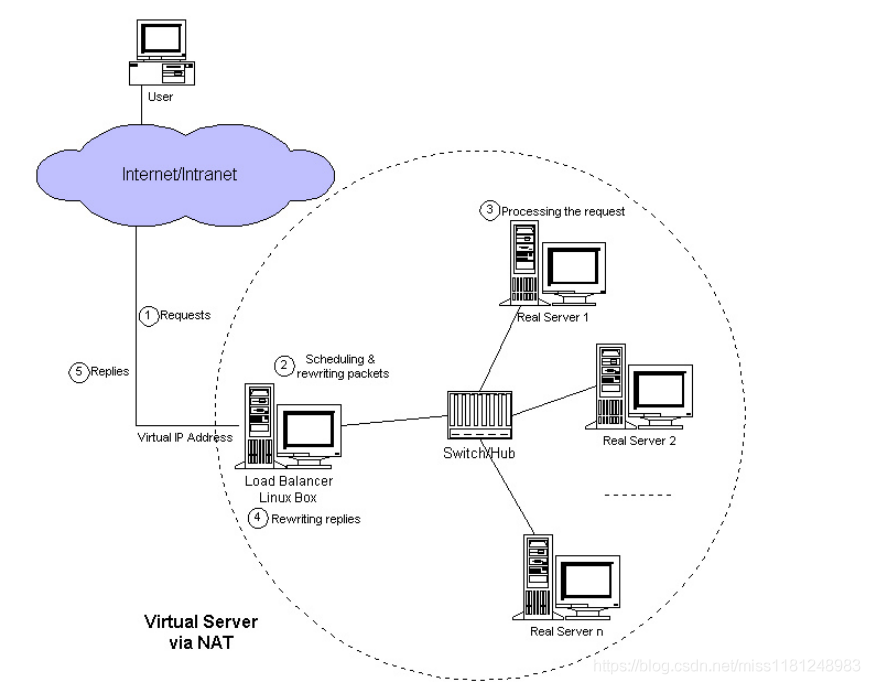
在這種模式下,負載均衡器上有設(shè)置iptables nat表的規(guī)則,實現(xiàn)了把用戶的請求數(shù)據(jù)包轉(zhuǎn)發(fā)到后端的Real Server(即WEB
Server)上,而且還要把WEB Server的響應數(shù)據(jù)傳遞給用戶,這樣負載均衡器很容易成為一個瓶頸,當并發(fā)量很大時,一定會
影響整個架構(gòu)的性能。
2)DR模式
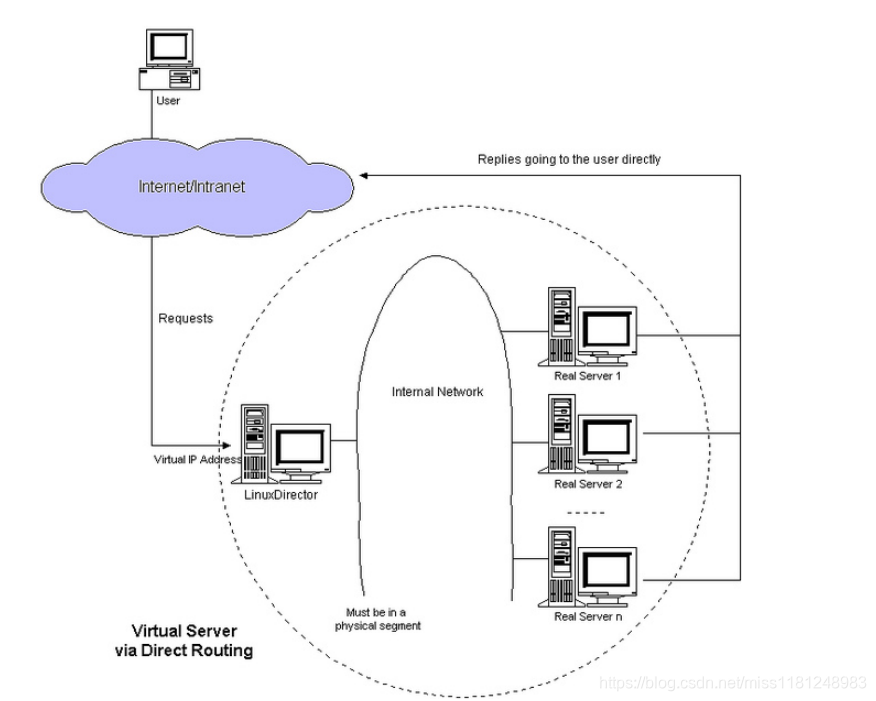
LVS的DR模式和NAT不一樣,負載均衡器只需要分發(fā)用戶的請求,而WEB Server的返回數(shù)據(jù)并不通過負載均衡器傳遞,數(shù)據(jù)直
接由WEB Server自己處理。這樣就解決了NAT模式的瓶頸問題。但是,DR模式有一個要求:負載均衡器和WEB Server必須在同一個內(nèi)部網(wǎng)絡(luò)(要求在相同的廣播域內(nèi)),這是因為DR模式下,數(shù)據(jù)包的目的MAC地址被修改為了WEB Server的MAC地址。
3)IP Tunnel模式
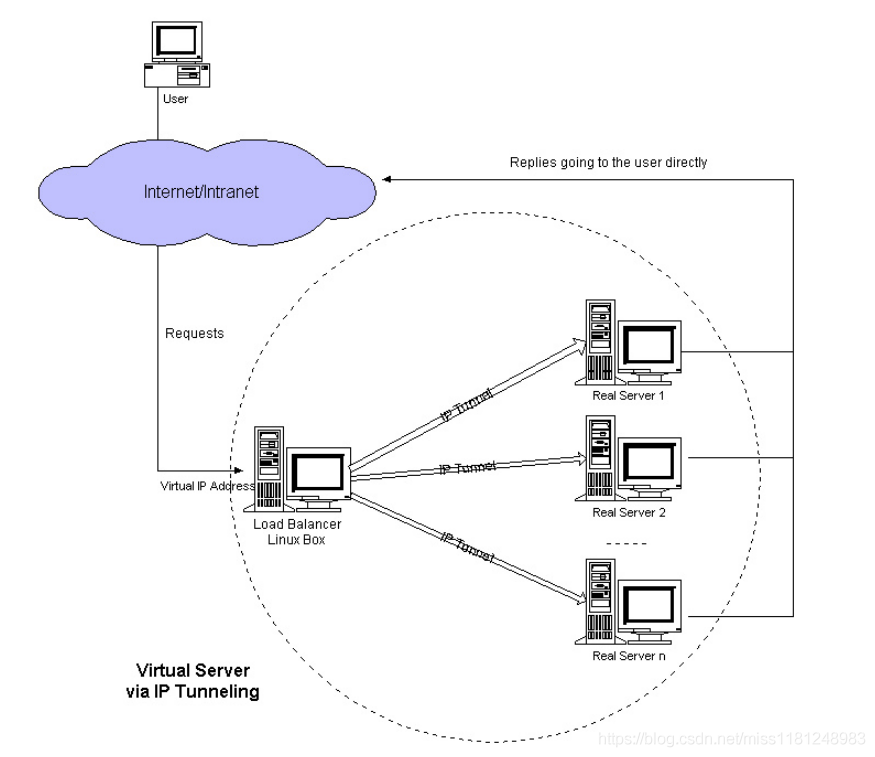
LVS的IP Tunnel模式和DR模式類似,負載均衡器只需要分發(fā)用戶的請求,而WEB Server的返回數(shù)據(jù)并不通過負載均衡器傳遞,數(shù)據(jù)直接由WEB Server自己處理。這樣就解決了NAT模式的瓶頸問題。和DR模式不同的是,IP Tunnel模式不需要保證分發(fā)器和Real Server在同一個網(wǎng)絡(luò)環(huán)境,因為這種模式下,它會把數(shù)據(jù)包的目的IP地址更改為Real Server的IP地址。這種模式,可以實現(xiàn)跨機房、跨地域的負載均衡。
對于以上三種模式來說,IP Tunnl模式更適合用在高并發(fā)的場景下。但有一點需要注意,這臺作為負載均衡器的服務(wù)器無論是自身的網(wǎng)卡性能,還是它所處的網(wǎng)絡(luò)環(huán)境里的網(wǎng)絡(luò)設(shè)備都有很高的要求。
可能你會有疑問,這臺負載均衡器終究只是一個入口,一臺機器頂多支撐10萬并發(fā),對于1000萬、2000萬的并發(fā)怎么實現(xiàn)?答案是:疊加!一臺10萬,100臺就是1000萬,200臺就是2000萬……
還有個問題,如何讓一個域名(如,www.google.com)訪問這200臺負載均衡器?請思考一下上一小節(jié)的CDN技術(shù),它就可以讓一個域名指向到成千上萬的邊緣服務(wù)器上。沒錯,智能DNS解析可以把全國甚至世界各地的請求智能地解析到最優(yōu)的邊緣服務(wù)器上。當然,DNS也可以不用智能,大不了直接添加幾百條A記錄唄,最終也會把用戶的請求均衡地分發(fā)到這幾百個節(jié)點上。
3. WEB層
如果最前端使用了CDN,那么在WEB這一層處理的請求絕大多數(shù)為動態(tài)的請求。什么是動態(tài)的請求?除了靜態(tài)的就是動態(tài)的,那什么是靜態(tài)的?前面提到過的圖片、js、css、html、音頻、視頻等等都屬于靜態(tài)資源,當然另外還有太多,大家可以參考第一篇文章《HTTP掃盲》的MIME Type。
再來說這個動態(tài),你可以這樣理解:凡是涉及到數(shù)據(jù)庫存取操作的請求都屬于動態(tài)請求。比如,一個網(wǎng)站需要注冊用戶才可以正常訪問里面的內(nèi)容,你注冊的用戶信息(用戶名、密碼、手機號、郵箱等)存入到了數(shù)據(jù)庫里,每次你登錄該網(wǎng)站,都需要到數(shù)據(jù)庫里查詢用戶名和密碼,來驗證你輸入的是否是正確的。
如果到了WEB這一層全都是動態(tài)的請求的話,那么并發(fā)量的多少主要取決于WEB層后端的DB層或者Cache層。也就是說要想提升WEB層服務(wù)器的并發(fā)性能,必須首先要提升DB層或者Cache層的并發(fā)性能。
我們不妨來一個假設(shè):要求架構(gòu)能支撐1000萬并發(fā)(動態(tài)),假設(shè)單臺WEB Server支撐1000并發(fā),則需要1萬臺服務(wù)器。實際生產(chǎn)環(huán)境中,單臺機器支撐1000并發(fā)已經(jīng)非常厲害啦,至少在我的運維生涯里,單臺WEB Server最大動態(tài)并發(fā)量并沒有達到過這么大。
我提供一組數(shù)據(jù),你自然就可以估算出并發(fā)量。在這我拿PHP的應用舉例:一個PHP的網(wǎng)站,單個PHP-FPM進程耗費內(nèi)存在2M-20M(假設(shè)耗費內(nèi)存10M),1000個并發(fā)也就意味著同時有1000個PHP-FPM進程,耗費內(nèi)存為1000*10M=10G,再加上留給系統(tǒng)1G內(nèi)存,所以1000并發(fā)至少需要11G內(nèi)存。
按照上面的估算,2000并發(fā)則需要21G內(nèi)存,10000并發(fā)則需要101G內(nèi)存,這個僅僅是理論值。實際上,并發(fā)量不僅跟內(nèi)存有關(guān)系,跟CPU同樣也有關(guān)系。如果服務(wù)器有4核CPU,則理論上僅僅支持4個進程同時占用CPU計算,也就是說僅能支持4個并發(fā)。當然,CPU計算那么快,進程會來回切換排隊占用CPU,這樣能夠?qū)崿F(xiàn)即使只有4核CPU,依然能夠支持幾百甚至上千的并發(fā)。但無論如何,CPU的核數(shù)越大,該服務(wù)器能支撐的并發(fā)也就越大。
對于高并發(fā)的架構(gòu),WEB Server必然會做負載均衡集群,單臺WEB Server的配置通常會選擇4核8G這樣的配置(這個配置,最好是根據(jù)自己業(yè)務(wù)的特性選擇合適的,畢竟現(xiàn)在大多企業(yè)都使用公有云或者私有云,服務(wù)器的配置可以定制),然后由這樣的機器來組成一個大型集群,最終實現(xiàn)高并發(fā)的需求。
4. Cache層
增加這一層的目的是為了減輕DB層的壓力,Cache層有一個特點:數(shù)據(jù)的讀寫發(fā)生在內(nèi)存里,跟磁盤并沒有關(guān)系。正是因為這個特點,保證了數(shù)據(jù)的讀寫速度非常快。假如沒有Cache層,并發(fā)1000萬的動態(tài)請求意味著這1000萬會直接透傳到DB層(如MySQL),1000萬的并發(fā)就會造成1000萬對磁盤的讀寫操作。我想大家都明白,磁盤的讀寫速度遠遠低于內(nèi)存的讀寫速度,要想支撐1000萬并發(fā)讀寫是不現(xiàn)實的。
當然,Cache層主要針對讀操作,而且它僅僅是緩存一部分DB層的熱數(shù)據(jù)(頻繁讀取的那部分數(shù)據(jù))。舉一個下例子:有一次公司的某個業(yè)務(wù)臨時做了一個推廣活動,結(jié)果導致訪問量暴漲10倍,原本的服務(wù)器架構(gòu)并不能支撐這么大的量,結(jié)果可想而知。當時,我們的解決方案是:把查詢量非常大的數(shù)據(jù)緩存到Memcached里面,然后在沒有增加硬件的情況下順利抗了過去。可見這一
個Cache層所起到的作用是多么關(guān)鍵。
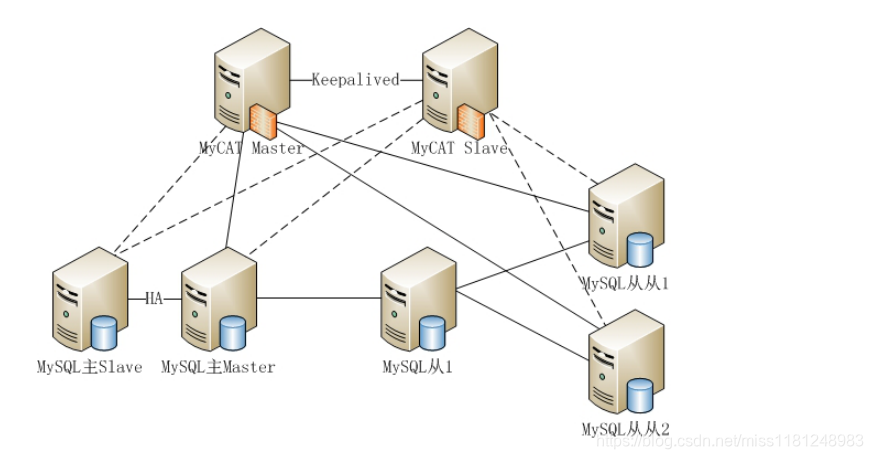
可以作為Cache的角色通常是NoSQL,如Memcached、Redis等。在第3章《常見WEB集群架構(gòu)》中我曾提到過Memcached,架構(gòu)圖如下:
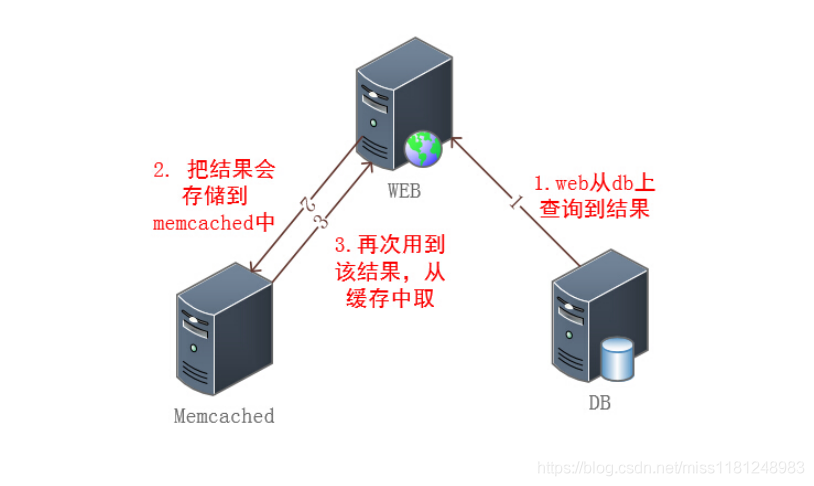
作為Cache角色時,Redis和Memcached用法基本一致。其實,拋開這個Cache角色,NoSQL也可以獨立作為DB層,這主要取決于業(yè)務(wù)邏輯是否支持拿NoSQL作為數(shù)據(jù)存儲引擎,畢竟NoSQL的數(shù)據(jù)結(jié)構(gòu)和關(guān)系型數(shù)據(jù)庫比還是比較簡單的,有些復雜場景無法實現(xiàn)。但為了實現(xiàn)高并發(fā),我們可以嘗試同時使用傳統(tǒng)的關(guān)系型數(shù)據(jù)庫和NoSQL數(shù)據(jù)庫存儲數(shù)據(jù)。
既然Memcached和Redis都可以作為Cache角色,那么到底用哪一個可以支撐更大的并發(fā)量呢?其實這兩者各有千秋,不能盲目地下結(jié)論說哪個更快或者更好。得根據(jù)你的業(yè)務(wù)選擇適合的服務(wù)。由于Redis屬于單線程,故只能使用單核,而Memcached屬于多線程的,從而可以使用多核,所以在比較上,平均每一個核上Redis在存儲小數(shù)據(jù)時比Memcached性能更高。而在100k以
上的數(shù)據(jù)中,Memcached性能要高于Redis,雖然Redis最近也在存儲大數(shù)據(jù)的性能上進行優(yōu)化,但是比起Memcached,還是稍有遜色。如果不考慮存儲數(shù)據(jù)大小,肯定Memcached性能更好,畢竟它是多線程的。
另外你需要了解,Memcached的數(shù)據(jù)只能存內(nèi)存,不能存到磁盤,而Redis支持把內(nèi)存的數(shù)據(jù)鏡像一份到磁盤上,而且還可以記錄日志(通過這個日志來獲取數(shù)據(jù))。Memcached只能存簡單的K-V格式的數(shù)據(jù),而Redis支持更多的數(shù)據(jù)類型(如,list、hash)。
無論你用哪一種作為Cache,我們都需要為其做一個高可用負載均衡集群,這樣才可以滿足高并發(fā)的需求。
5. DB層
可以說DB層是整個架構(gòu)體系中非常關(guān)鍵的一層,也是瓶頸所在。原因無他,只因它涉及到對磁盤的讀寫。所以,為了提升性能,對服務(wù)器磁盤要求很高,至少是15000r/m的SAS硬盤而且需要做RAID10,如果選擇SSD盤更優(yōu)。
最簡單暴力提升并發(fā)數(shù)量的辦法是服務(wù)器的堆積(即,做負載均衡集群),但DB層跟WEB層不一樣,它涉及到數(shù)據(jù)存儲到磁盤
里,服務(wù)器可以累加,但是磁盤在累加的同時,如何保證所有的服務(wù)器能讀寫同一份數(shù)據(jù)?這是一個很大的問題,所以單純的服務(wù)器堆積只適合小規(guī)模的業(yè)務(wù),對于并發(fā)上千萬的業(yè)務(wù)并不適用。并發(fā)量大的站點,意味著數(shù)據(jù)量也是非常大的(如,TB級別),如果單個數(shù)據(jù)庫上TB,那一定是一個災難,無論是讀寫還是備份都將是極大的問題。
那如何解決這個問題呢?既然大了不行,那就將大的庫切割成小的庫即可。你可不要把這個切割單純地想象成切割文件。我們可以從兩個維度來實現(xiàn)切割。
1)將業(yè)務(wù)劃分為多個業(yè)務(wù)模塊
大型網(wǎng)站為了應對日益復雜的業(yè)務(wù)場景,通過使用分而治之的手段將整個網(wǎng)站業(yè)務(wù)分成不同的產(chǎn)品線,如大型購物網(wǎng)站就會將首頁、商鋪、訂單、買家、賣家、倉儲、物流、售后服務(wù)等拆分成不同的產(chǎn)品項,這樣數(shù)據(jù)庫自然也拆分為了多個數(shù)據(jù)庫,原來TB級的數(shù)據(jù),變成了GB級。如果覺得還不夠細化,我們可以繼續(xù)把商鋪進一步拆分,比如個人類的、企業(yè)類的、明星類的、普通類的等等。總之,你可以根據(jù)業(yè)務(wù)特性想到幾百種拆分方法,最終一塊大蛋糕變成了幾十甚至幾百塊小蛋糕,吃起來就簡單多了。
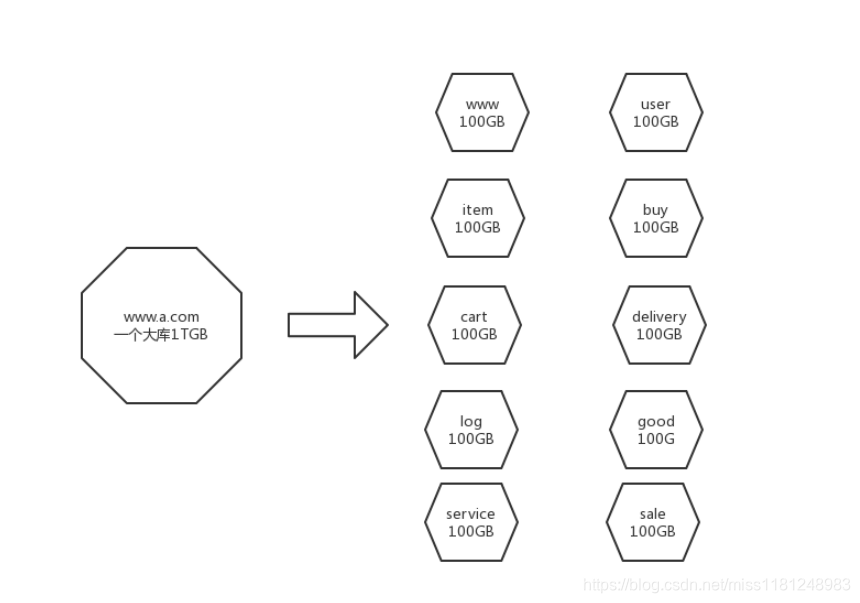
2)將數(shù)據(jù)庫分庫分表
業(yè)務(wù)拆分是產(chǎn)品經(jīng)理設(shè)計的,但是這個分庫分表只能是DBA操刀。如果一個幾千GB的大庫讀寫很慢的話,但分成1000個幾GB的小庫后,讀寫速度一定是有質(zhì)的飛躍。同理,表也是可以像庫那樣劃分的。分庫分表需要借助數(shù)據(jù)庫中間件來完成。比如MySQL分庫分表比較好的中間件MyCAT就不錯。
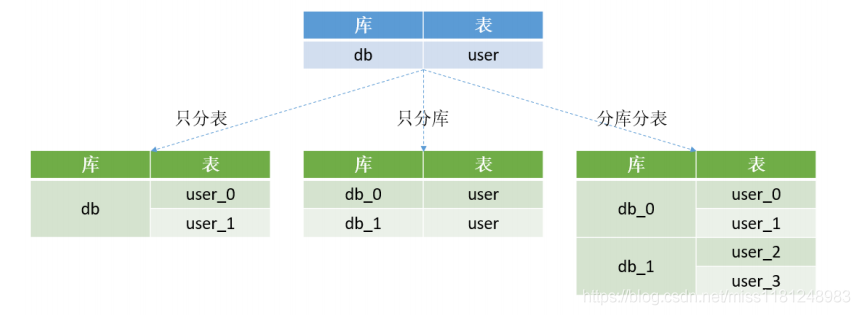
有了以上兩個拆分原則,無論多大的庫,我們都可以劃分為比較小的庫,這樣即使使用傳統(tǒng)的架構(gòu)依然可以輕松應付。最終的DB層架構(gòu)就成了蜂窩狀的一組一組的小單元,每一個單元獨立做高可用以及負載均衡集群。
6. 消息隊列層
一個大型的網(wǎng)站,一定少不了消息隊列這一層。在前面第3章《常見WEB集群架構(gòu)》一文中就提到過它,它主要解決的問題是:解耦合、異步處理、流量削峰等。以下三個應用場景曾在第3章出現(xiàn)過,也許你現(xiàn)在看會有更深層次的體會。
1)解耦合應用場景示例
用戶上傳圖片到服務(wù)器,要求人臉識別系統(tǒng)識別該上傳圖片,傳統(tǒng)的做法是:用戶上傳圖片 → 服務(wù)接收到圖片開始識別圖片 → 系統(tǒng)判斷圖片是否合法 → 反饋給用戶是否成功。這個要涉及兩個系統(tǒng):

而使用消息隊列,流程會變成這樣:

用戶上傳圖片后,圖片上傳系統(tǒng)將圖片信息寫入消息隊列,直接返回成功;而人臉識別系統(tǒng)則定時從消息隊列中取數(shù)據(jù),完成對新增圖片的識別。
此時圖片上傳系統(tǒng)并不需要關(guān)心人臉識別系統(tǒng)是否對這些圖片信息的處理、以及何時對這些圖片信息進行處理。事實上,由于用戶并不需要立即知道人臉識別結(jié)果,人臉識別系統(tǒng)可以選擇不同的調(diào)度策略,按照閑時、忙時、正常時間,對隊列中的圖片信息進行處理。
2)異步處理應用場景示例
用戶到一個網(wǎng)站注冊賬號,系統(tǒng)需要發(fā)送注冊郵件并驗證短信。傳統(tǒng)的處理流程如下:

這種方式下,需要最終發(fā)送短信驗證后再返回給客戶端。
另外一種方式就是異步處理,即注冊郵件和短信同時發(fā)送,流程如下:
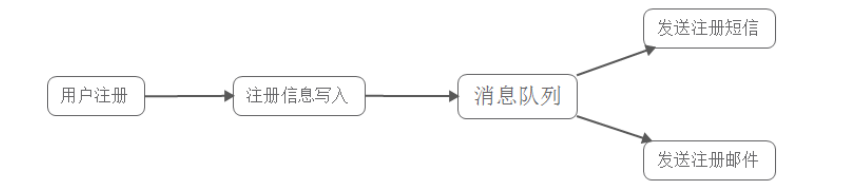
當用戶填寫完注冊信息并成功寫入消息隊列后,就可以反回成功的信息給客戶端,從而客戶端不需要再等待系統(tǒng)發(fā)郵件和發(fā)短信,不僅客戶端不用等,而且處理客戶端請求的那個工作進程也不需要等(這個特性非常重要,它是實現(xiàn)高并發(fā)的一個重要手段),這個就是異步處理的優(yōu)勢。
3)流量削峰應用場景示例
很典型的應用就是購物網(wǎng)站秒殺活動,一般由于瞬時訪問量過大,服務(wù)器接收過大,會導致流量暴增,相關(guān)系統(tǒng)無法處理請求甚至崩潰。而加入消息隊列后,系統(tǒng)可以從消息隊列中取數(shù)據(jù),相當于消息隊列做了一次緩沖。

該方法可以讓請求先入消息隊列,而不是由業(yè)務(wù)處理系統(tǒng)直接處理,極大地減少了業(yè)務(wù)處理系統(tǒng)的壓力。另外隊列長度可以做限制,比如隊列長度為100,則該系統(tǒng)只能有100人可以秒殺到商品,排在100名后的用戶無法秒殺到商品,而返回活動已結(jié)束或商品已售完的信息。
總之,消息隊列的引入極大提升了整個架構(gòu)的并發(fā)能力。從WEB層接收到動態(tài)的請求后,Cache層過濾掉一部分,然后請求逐一地發(fā)送到DB層,在這個過程中,查詢時間很長的請求可以單獨摘出來,把它搞到消息隊列里,這樣WEB層和DB層只處理那種快速有結(jié)果的查詢,并發(fā)量自然很大。而消息隊列會慢慢消化掉這些特殊的查詢,或許你有疑問,這種查詢慢的請求也很多怎么
辦?不也同樣影響到并發(fā)量嗎?畢竟最終的查詢到了DB層。不要忘記消息隊列本身就有削峰的能力,如果有大量的這種查詢,那么就讓它們排好隊列,慢慢消化,總之不讓它們影響到DB層的正常查詢。
可以提供消息隊列的服務(wù)有那么多(RabitMQ、ActiveMQ、Kafka、ZeroMQ、MetaMQ、Beanstalk、Redis等等),到底選擇哪一種?最好是讓研發(fā)同事來定吧,只有研發(fā)團隊最了解自己代碼的邏輯架構(gòu),適合自己的才是最好的。事實上,無論你用哪一種消息隊列服務(wù),它都不會成為整個架構(gòu)的瓶頸點。當然,你最好做一個分布式的集群,這樣能夠保證它的橫向擴容或者縮容。
7. 存儲層
關(guān)于存儲,目前的解決方案我歸類為以下幾種:
1)服務(wù)器本地存儲
就是服務(wù)器自身的磁盤,對于像DB層這樣關(guān)鍵的角色,我們通常會用高性能磁盤做RAID10。特點:方便維護、穩(wěn)定、性能非常好、容量有限、擴容不方便。
2)專業(yè)的存儲設(shè)備
主要有三類:NAS、SAN、DAS。
NAS:類似Linux系統(tǒng)做的NFS服務(wù),它是建立在操作系統(tǒng)層面上的一種共享存儲解決方案,它是一種商業(yè)產(chǎn)品。NAS比較適合小規(guī)模網(wǎng)站。特點:容量大、擴容不方便、吞吐量一般(受網(wǎng)絡(luò)環(huán)境影響)、穩(wěn)定性好、成本高。
SAN:也是一種商業(yè)的共享存儲解決方案,支持普通網(wǎng)絡(luò)或者光纖接入,比NAS更加底層。特點:容量大、擴容不方便、性能好(比NAS強很多)、穩(wěn)定性好、成本高昂。
DAS:磁盤陣列,支持RAID,商業(yè)的存儲。特點:容量大、擴容不方便、不支持共享、性能好、穩(wěn)定性好。
3)分布式共享存儲
隨著云計算、大數(shù)據(jù)技術(shù)的日益流行,分布式共享存儲技術(shù)越來越成熟,無論是商業(yè)的還是開源的都有不少優(yōu)秀的解決方案。比如,開源的有HDFS、FastDFS、MFS、GlusterFS、Ceph、Swift等。這類存儲有一些共同特點:方便擴容、容量可以無限大、性能一般(網(wǎng)絡(luò)會成為瓶頸)、成本低、穩(wěn)定性好。
本節(jié)的存儲層我也歸類為三大類:WEB層面的存儲(比如存儲代碼、圖片、js、css、視頻、音頻等靜態(tài)文件)、日志、DB層面的存儲(即數(shù)據(jù)庫的數(shù)據(jù)存儲)。
這三類存儲,最要命的是DB層的存儲,前面我也提到過DB層很關(guān)鍵,而決定DB層性能的因素中這個數(shù)據(jù)存儲(磁盤)性能起到?jīng)Q定性作用。解決方案我也提到了,就是“大變小,一變多,自己管自己”。正常情況下巨量的數(shù)據(jù)庫必然會使用大容量存儲設(shè)備,這樣最終的結(jié)果是—慢!所以,我們需要分模塊、分庫分表,最終單臺機器的本地磁盤就可以支撐這些巨量的數(shù)據(jù),讀寫速度不會被網(wǎng)絡(luò)等因素影響。
日志類和WEB層靜態(tài)文件的存儲可以選擇分布式共享存儲解決方案,因為這類的存儲不需要太高的吞吐量,它們所占用的空間比較大,而且會越來越大。
總結(jié)
當你看完以上內(nèi)容后,可能你的心中還是沒有一個完整的答案,所以這個總結(jié)很關(guān)鍵!
1)高并發(fā)網(wǎng)站一定會使用CDN,而且需要把靜態(tài)文件存儲在邊緣服務(wù)器上。
2)負載均衡一定要使用四層的,比如LVS,如果是LVS,選擇IP Tunnel模式。
3)WEB層把靜態(tài)的請求交給CDN處理,所以只處理動態(tài)的請求,要支持橫向擴容,可以方便地通過加機器來增加并發(fā)量。
4)增加Cache層,把熱數(shù)據(jù)搞到這一層,減少對DB層地壓力。對這一層做分布式集群架構(gòu)設(shè)計,方便擴容。
5)增加消息隊列,實現(xiàn)解耦合、流量削峰,從而提升整個架構(gòu)地并發(fā)能力。
6)DB層要通過拆分業(yè)務(wù)、分庫分表來實現(xiàn)大變小、一變多,對單獨模塊做高可用負載均衡集群,從而提升并發(fā)能力。
7)DB層的存儲使用本地磁盤,日志類、靜態(tài)文件類使用分布式文件存儲。